【論文】Llama2 が 100k トークン入力可能に!? 高コスパ手法 LongLoRA の紹介
はじめに
LongLoRA は 9/21 に arXiv に投稿された論文で、この手法によって なんとたった 8 枚の A100で学習済み Llama2-7B の最大入力トークンを 10 万トークン に fine-tuning 出来るらしいです(元々 4096 トークンまでしかできない)。 これのどこが凄いのかというと、GPT-4 でさえ最大 3.2 万トークンで、長文を入力できる超高性能 LLM と言われる Claude2 の最大入力トークンに匹敵しているということです。そして、それがたった 8 枚の A100 で実現できるということです。 8 枚の A100 というと個人だと本当に一握りの人が出来るようなレベルだと思いますが、AI に力を入れている企業レベルであれば簡単に使用できると思うので、今まで特定の企業しか手を出せなかった領域により多くの企業が参加できるようになりそうです。
概要
arxiv page: URL
新規性は主に以下の 3 点です。 これらの提案によって低コストで学習済み LLM を長い入力トークンを扱えるように fine-tuningすることが可能になります。
- 超シンプルかつ汎用性の高い Shift Short Attention の提案
- コンテキストが長い環境でのより良い LoRA+ の提案
- 長コンテストの新しいデータセット LongQA の構築
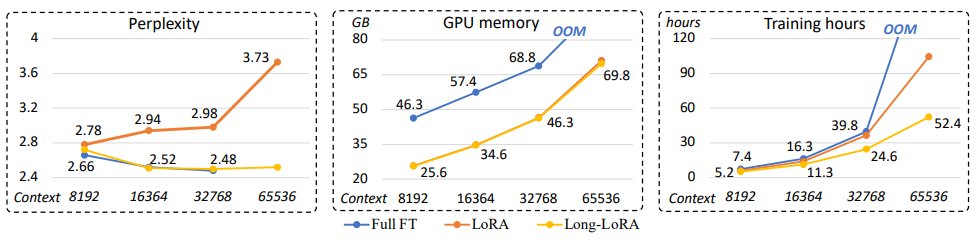
上図:Full fine-tuning、通常 LoRA、LongLoRA の比較
LongLoRA では入力トークン長が伸びても Full fine-tuning と同等の性能を保っている上に、低メモリかつ低計算量を実現していることがこの結果からわかります。
学習済み LLM の入力長は変えられるの?
そもそものトピックで気になるのが、既に学習された LLM の入力トークン長は変えられるのか?ということです。この領域はあまり詳しくはなかったのですが、最近の論文で学習済み LLM のトークン長を伸ばす手法がいくつか提案されています。
- Extending Context Window of Large Language Models via Positional Interpolation
- Focused Transformer: Contrastive Training for Context Scaling
- Landmark Attention: Random-Access Infinite Context Length for Transformers
ただし、これらの手法はトークン長を伸ばすために大量の計算資源を必要とするという欠点があります。例えば一番上の Positional Interpolation という手法は、Llama の入力長を 2k から 8k へ伸ばすために 32 個の A100 を使用しており、それ以上のトークン長では 128 個の A100 を使っているそうです。
そして、LongLoRA では学習済み LLM の入力長を伸ばすためにこの Positional Interpolation を使用していますが、その際に必要な計算資源は前述の通り 8 枚の A100 という驚異的な低コストで実現しています。 なぜこのような低コストを実現できたのか、その特徴を見ていきましょう。
Shift Short Attention
Transformer の大きなボトルネックは Self-attention の計算で、入力トークン長の 2 乗であるO(n^2)の計算量とメモリが必要になるのは有名な話です。
そのため、LongLoRA でも入力トークン長を伸ばすために Self-attention の計算量を削減する手法を提案しています。
LongLoRA では Shift Short Attention という手法を提案しており、以下のようなイメージです。
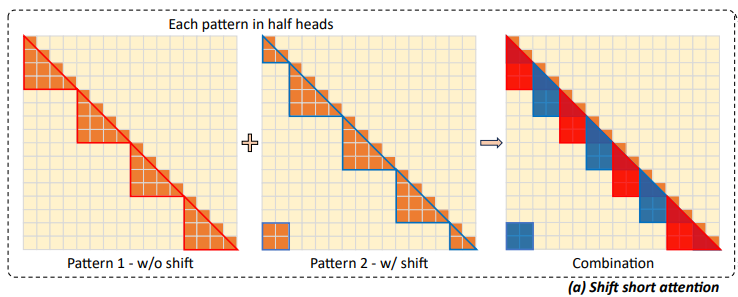
上図:Shift Short Attention のイメージ
Shift Short Attention では2つの Attention パターンを組み合わせています。パターン 1 は論文中では Short Attention と呼ばれており、全トークンを複数のグループに分け、そのグループ内で Self-attention をします。
これ単体に関してはシンプルなのでもしかしたらどこかの論文で既に提案されてるかもしれません。
例えば、LongFormerでは以下のような Attention パターンが 2020 年に既に提案されています。
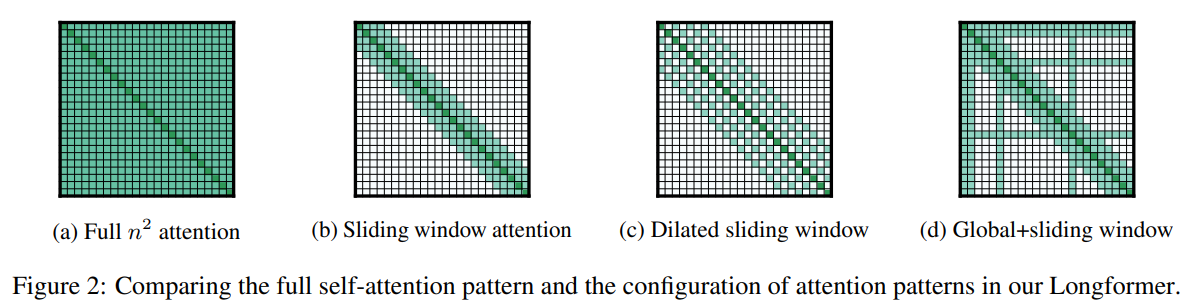
Shift Short Attention ではパターン 2 のグループの作成場所がずれたバージョンの short attention も組み合わせます。パターン 1 のみの attention だと、グループ内で attention が閉じてしまい情報の欠落が発生しそうですが、ずらされたグループを持つパターン 2 を組み合わせることで attention がグループを跨いで実施されるようになります。 最終的に LongFormer の Sliding Window Attention と微妙に似たような形になります。グループという大きな括りで Full-attention をするか、sliding window という小さな括りで Full-attention をするかの違いですかね。(また、グループはトークンごとに sliding しないのでそこも違う)
ポイントは、Multi-head Attention の実施の際に、半分の head でパターン 1 の Attention をし残りの半分の head でパターン 2 の Attention をすることで、Multi-head Attention の計算量を変えずに実施することが出来る点です。また、アーキテクチャ的には Full Attention と同じ形なので FlashAttention 等の手法と共存することができます。
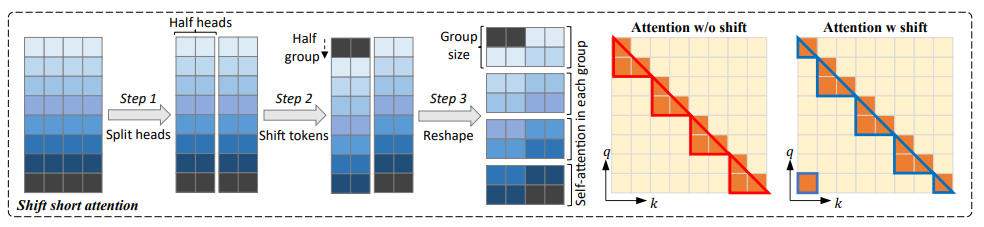
この Shift Short Attetion ですが、超簡単に実装することが出来ます。
- Multi-head Attention の head 数を半分に分ける
- 分けた半分の head の特徴量を
(feature_dim / group_num)/2の分だけずらす - 分けた 2 つの head を再度結合し、特徴量次元方向に Group 数分だけ分割する
- それぞれの Group で Self-attention を実施する
これは PyTorch でとてつもなくシンプルに以下のように実装が可能です。

このように簡単に実装できる Shift Short Attention ですが、実際の性能もかなり高いです。以下の結果は Full Attention と Short Attention、Shift Short Attention の比較です。 Shift Short Attention を採用することで、Full Attention よりも大幅に計算量は減りますが精度という面ではほぼ変わらないという結果になっています。
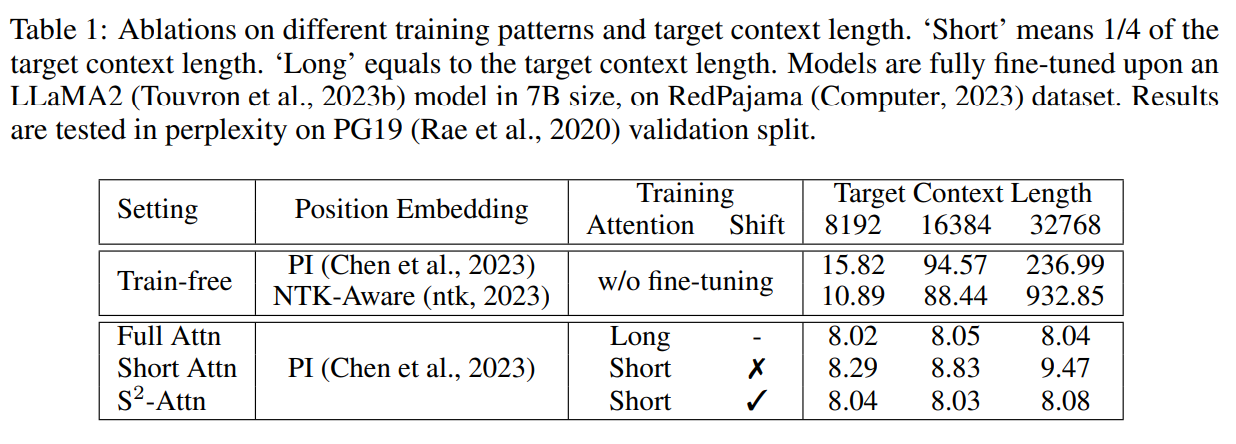
また、他の Attention 効率化手法と比較しても高い性能を持っていることが分かります。そして、この Shift Short Attention の面白い結果も出ていて、fine-tuning 時に Shift Short Attention で学習して、推論時に Full Attention にしても精度は落ちずにむしろ向上しているそうです。
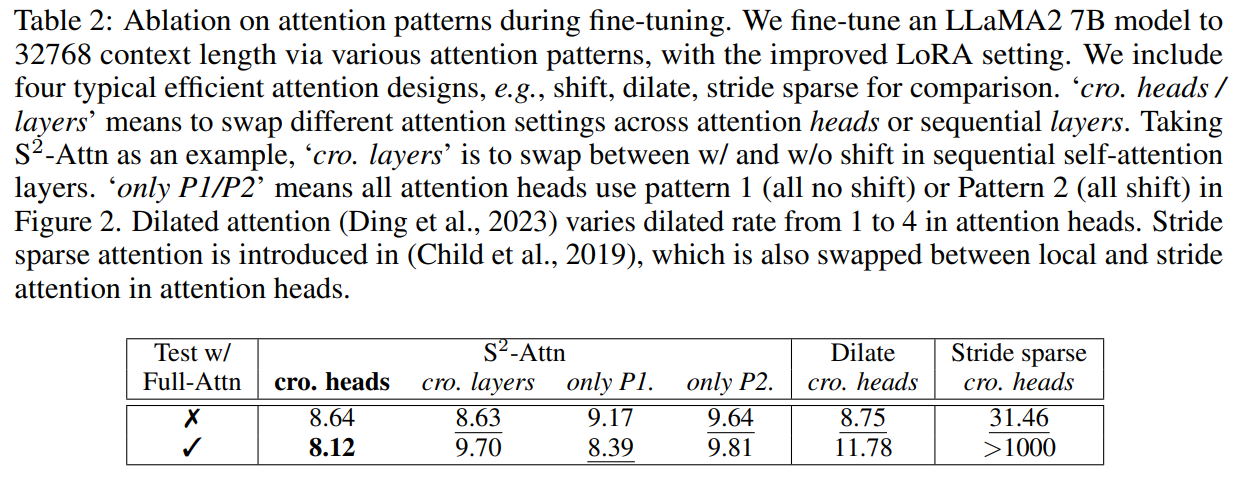
LoRA+
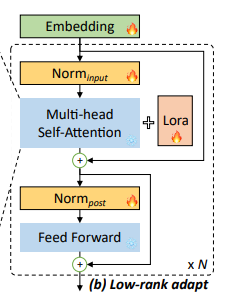
LoRA は fine-tuning 時に全ての重みを更新するのではなく、重みよりもパラメータ数が少ない低ランク行列で近似する手法です。特に Transformer では Attention の projection の重みを近似することが多いです。(LoRA の提案論文がそう実装している) しかし、LongRoRA の筆者たちの実験でこの LoRA を projection だけではなく、embedding 層と normalization 層にも適用することで精度が向上することを確認したそうです。
以下の画像の炎の絵文字の層に LoRA を適用しています。
そして embedding 層と normalization 層にも LoRA を適用することで、以下のように大幅に精度が向上しています。
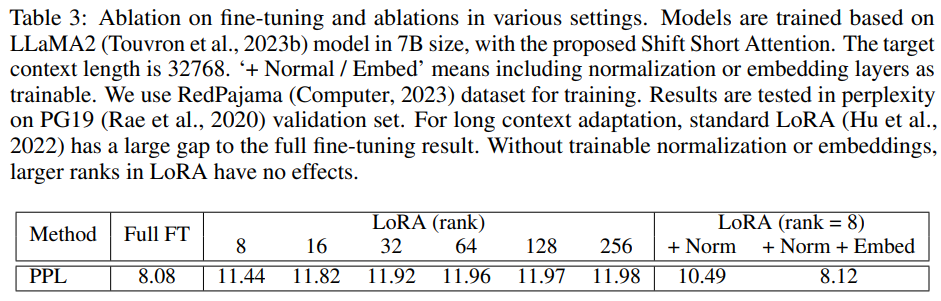
このようにただ LoRA の適用箇所を追加しただけですが、大きな精度向上が見られるのは驚きです。ただ、もしかしたら他の論文等で既に提案されているのかもしれません。
実験結果
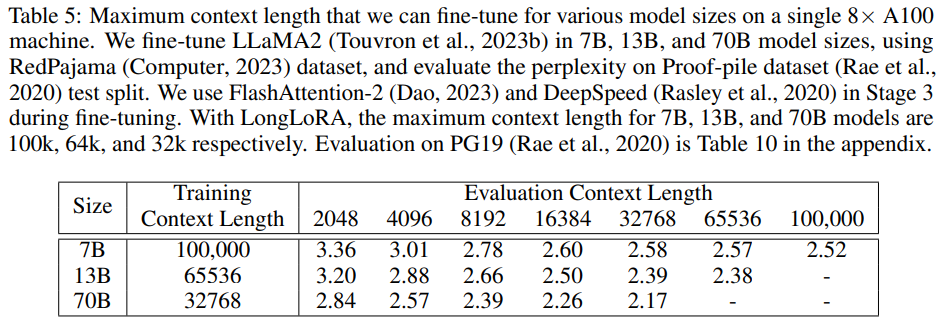
実験では Llama2 の 7B, 13B, 70B に対して最大トークン長を伸ばす fine-tuning を実施しました。使用しているリソースは前述した通り 8 枚の A100 です。また、入力トークン長を伸ばすために Position Interpolation という手法を使用し、Redpajama データセットを使用し 1000 ステップの fine-tuning を実施したそうです。
以下の表では proof-pile dataset での perplexity の結果です。Shift Short Attention と LoRA+をそれぞれ適用するごとに低計算量になる一方精度が下がるトレードオフがありますが、入力トークン長 8192 の結果を見てみると精度の低下はかなり小さいことが分かります。

そして次の実験では 8 枚の A100 で学習可能な上限長まで伸ばした各パラメータの比較を行っています。Llama2 の 7B では 100k トークンまで学習出来ていることが分かります。
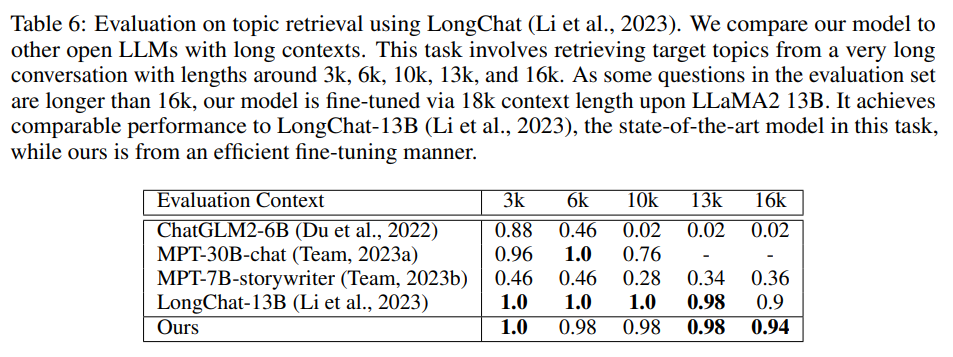
また、他のモデルとの比較も行っており、長コンテストモデルで SoTA モデルである LongChat-13B と同等の性能を Llama2-13B の LongLoRA によって達成しています。
まとめ
LongLoRA では低コストで学習済み LLM を長い入力トークンを扱えるように fine-tuningするために以下の 3 つの提案を行っていました。
- 超シンプルかつ汎用性の高い Shift Short Attention の提案
- コンテキストが長い環境でのより良い LoRA+ の提案
- 長コンテストの新しいデータセット LongQA の構築
所感
シンプルだけど効果的な手法だと感じました。Llama2 が出てまだ 2 ヵ月ぐらいですが、コンテキスト長を伸ばす手法やそのコンテキスト長を伸ばす手法の低コスト化の論文が出たりとこの分野の研究スピードをとても感じます。 評価の部分では基本的に perplexity での評価になっているので、多くの LLM に使われている評価データセットなどを用いた評価は実施するべきだとは思います。また、LongLoRA の提案手法は他のモデルにも適用できるのかも気になってます。 特に画像系モデル(Stable diffusion)は LoRA が活発なので、LoRA+を適用するともっと精度が上がるのでしょうか・・?