【論文】Llama2 から学ぶ最新大規模言語モデル
概要
Llama2 とは 7/26 日に Meta が公開した大規模事前学習済みモデルです。ちなみに読み方はラマです(始めて見たときはエルラマ!?って思ってましたが、動物のラマって Llama らしいですね)。 Llama2 は公開されているモデルの中では英語においてトップクラスの性能を誇っているそうです。 Llama1 の発表から半年を経たずにアップデートされた Llama2 ですが、何が変わったのか論文を読んでまとめました。
大規模言語モデルとは?
大規模言語モデル(LLM: Large Language Model)とは、一言で言うと「大量のテキストデータを学習させた、入力された文章の続きを生成する AI モデル」のことです。1 回の生成では文章に続く次の 1 単語(正確には 1 トークン)を予測することしかできませんが、生成した単語を再度入力として扱うことで、自身で生成を繰り返すことができ長い文章を生成することができます。 最近 LLM という言葉をよく聞くようになりましたが、個人的には大きく話題になったのは 2019 年の GPT-2 の発表からだと思っています。この時は OpenAI は GPT-2 のモデルを公開しなかったのですが、その理由が「文章生成の精度が高すぎたため悪用される可能性がある」ということでした。
参考: 当時の記事
LLM に関連する論文は近年爆発的に増加している1
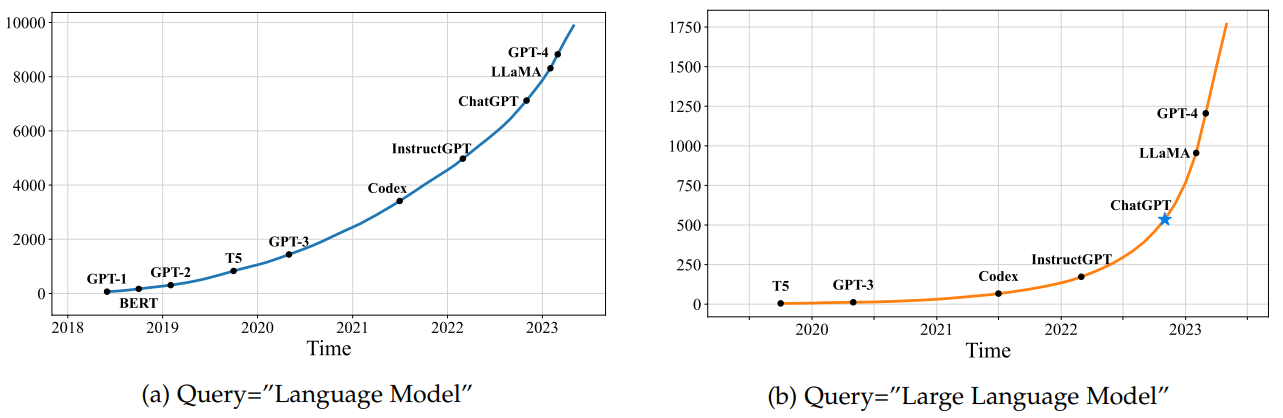
まだこの頃の LLM は単に次の単語を予測するだけのモデルで用途としては文章執筆程度だと思われていて応用は限られていました。しかし、2020 年に入ってからは GPT-3 の発表や、GPT-3 を使った様々な応用が話題になり、LLM の応用範囲が広がってきました。また、ChatGPT が発表され気軽に試すことが出来るようになってから一般の人にも爆発的に広がりました。ポイントとしてはスケーリング則と呼ばれる、モデルのパラメータ数/データ量/計算量を増やすことでモデルの精度が急速に向上するということが分かってきたことです。そのため、より大規模なデータセット、より大規模なモデル、より大規模な計算資源を費やすことで、より高い精度のモデルが作れるようになってきました。LLM は次の単語を予測するモデルで学習データは人間が書いた文章であれば何でも良く、それを教師なし学習できるため Web 上の文章を大量に集めることで大規模なデータセットを作ることができます。
LLM の発展1
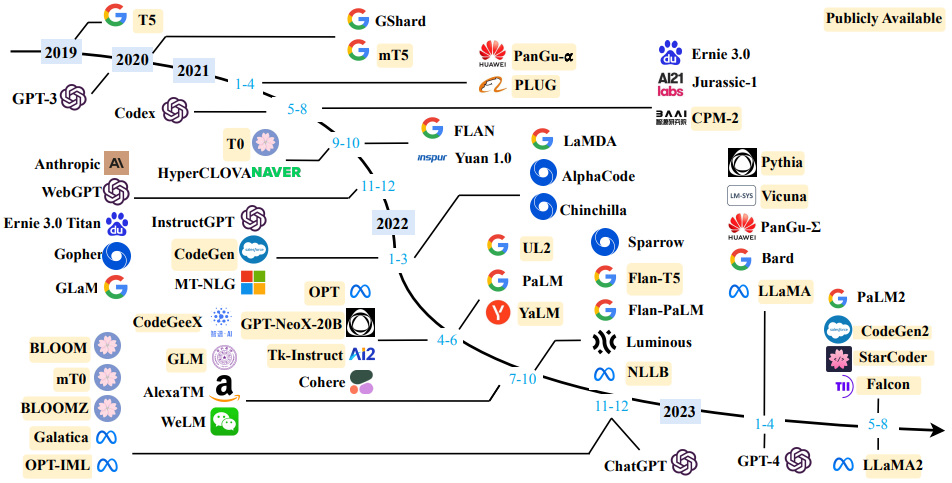
そして、ここからより"賢い AI"となるために様々な手法が提案されています。Instruct tuning や RLHF(Reinforcement Learning from Human Feedback)という手法で、Instruct tuning ではあるタスクを解く指示の内容とその返答が正解データとして与えられたデータセットを使って教師あり学習をします。論文としてはFLANなどで提案されました。
FLAN で使われたプロンプトの例(日本語翻訳)
入力
ジョーイ・ハインドル(1993 年 5 月 14 日、ミュンヘン生まれ)はドイツの歌手。ゲーム番組「Ich bin ein Star - Holt mich hier raus!」の第 7 シーズンで優勝したことで知られ、「Deutschland sucht den Superstar」のシーズン 9 では、毎週審査員から酷評されながらも 5 位に入賞した。 上の段落から、「ジョーイ・ハインンドルはテレビでは非常に嫌われていた」と結論づけられるだろうか?と結論づけられるか?
選択肢
- はい
- 不可能
- いいえ
出力
はい
単純に Web の記事を学習した言語モデルは学習データと同じように記事の続きなどを生成しますが用途としてはかなり限られてしまいます。一方で、このように"指示"とその"回答"が含まれた特殊な形式のデータセットを追加で学習することで、LLM は"タスクを解く"ことを学習します。私の個人的なイメージは、人が LLM に"指示プロンプトに従って回答する"振る舞いをしてほしいですが、事前学習のデータセットにはそのようなデータはほとんどないので、fine-tuning の形式で学習しているという形です。そして、実際に使うときは入力を”出力: ”のような形で終わらせることで、LLM にタスクの回答を出力させることを促すことが出来ます。モデルのインターフェース的には続きの文章を生成するということに代わりが無いのですが、タスクの回答を次に出力するようにプロンプトを与えることであたかも"タスクを解くために考えて出力をする"ふるまいになり、より応用範囲が広がり人間の様々なタスクを解くことができるようになります。理論的にはテキストに落とし込めるようなタスクであれば、そのタスクを解くための指示と回答を与えることでどのようなタスクでも解くことができるようになります。
ただしこの手法では、データセットの構築にコストがかかりデータの多様性が低いといった問題点があります。LLM のスケーリング則にはデータ量が重要だと前述しましたが、Web クローリング等でデータを集められない指示データセットはどうしても少量となってしまいます。その問題の対策として強化学習を使った RLHF という手法も提案されています。RLHF には様々な手法がありますが、例えばモデルに同じ質問に対し複数の回答をしてもらい、その回答に対して人間が点数を付け、いい回答をするように学習させるという手法があります。詳しくはInstructGPT の論文に説明があります。
RLHF の例2
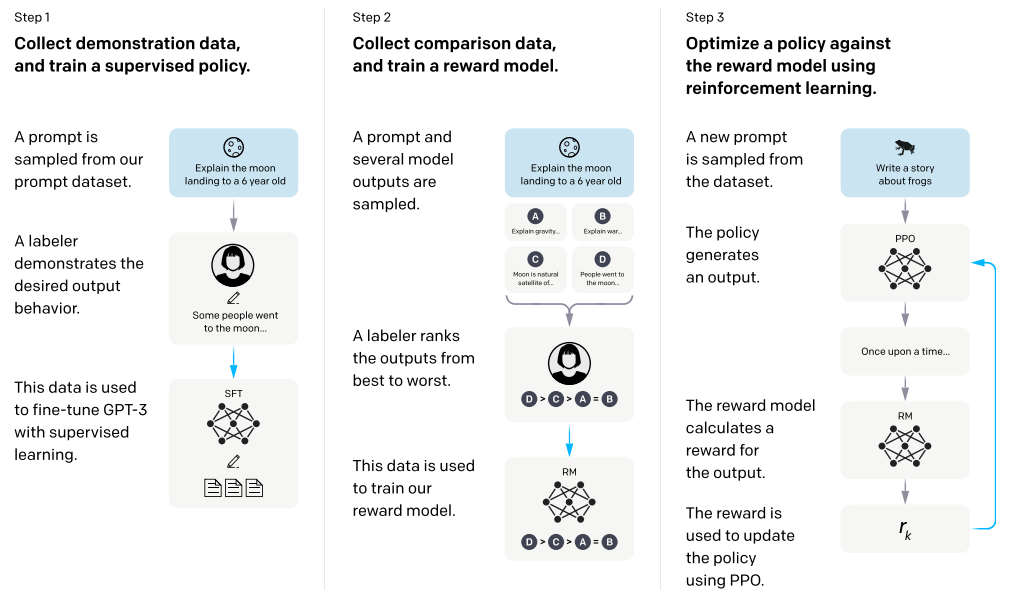
これらの手法によって学習されたモデルは 10 倍以上のパラメータ数のモデルと同等以上の性能を示すなどの報告がされています。直観的にはこれらの tuning を実施することにより、単に文章の続きを生成するモデルではなくより人間らしいモデルになったと感じます。
OpenAI のモデルの発展1
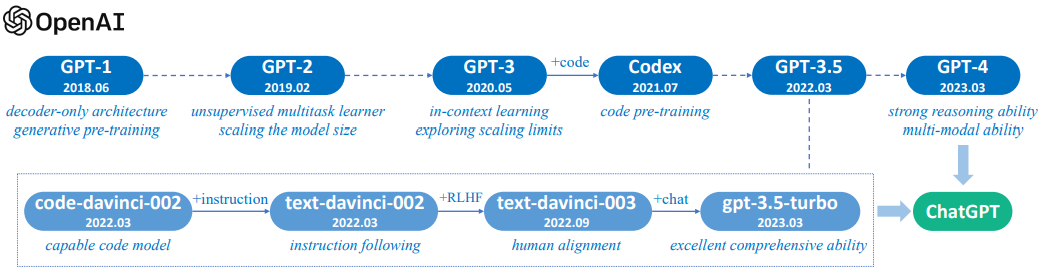
LLM の世界を牽引してきたのは間違いなく OpenAI でしょう。Google や Meta も重要な論文、モデルを発表したりしてきましたが GPT 系列のモデルで話題を作ってきました。
LLM の課題
このようにして次の単語しか生成できないモデルからより高度な応用ができるモデルへと進化してき、その応用の広さから大きな注目を集めています。ただ、まだまだ課題も多く実社会に応用しようとすると色々難しい点があります。
- 入出力の長さに制限があること
- モデルサイズが大きいこと
- 入出力がテキスト情報に限られること
現時点で最も大きな課題はやはり入出力の制限だと思います。有名な話ですが Transformer の Self-attention では内積を行うので、入力トークン数 x 入力トークン数のサイズの行列が出来ます。つまり入力トークン数の 2 乗の数の浮動小数点数を保存する必要があるのですが、これが多くのメモリを占有してしまうため容易に増やすことが出来ないのです。最近の研究ではこれを削減する手法も様々提案されていますが、基本的には精度とのトレードオフになってしまうのでなかなか解決が出来ていません。
次にモデルサイズですが、高い性能を得るにはモデルサイズは大きくする必要があります。ほとんど全てのモデルでモデルサイズを大きくすればするほど性能は上がっていきます。研究目的であればそれでいいのですが、社会実装する場合はそのサイズが大きくボトルネックとなります。例えば一般消費者が手に入れることが出来る GPU で最も性能が高いのは RTX4090 ですが、この GPU メモリは 24GB です。この時この GPU に乗るモデルは 32bit で読み込むとして 70 億パラメータぐらいです。130 億のモデルになると量子化等をして読み込む必要があります。Llama2 の最大モデルは 700 億パラメータですし、GPT-3 は 1750 億パラメータです。これらのモデルを一般消費者が使うにはまだまだハードルが高いですし、これらを動作させるには大きな計算資源が必要で費用もかかります。
最後は入出力がテキスト情報に限られることです。GPT-4 はマルチモーダル(テキストと画像)で学習されてるとのことなので、全てのモデルが出来ないわけではありません。ただ、現時点では多くのモデルは入出力はテキストだけなので、LLM の応用を考えるときはテキスト情報に限られるということを考慮する必要があります。アイデアとしては画像や動画を含めて色々やりたい、というのはあるのですが、現時点ではまだまだ難しいです。
Llama1 の登場
GPT-3 は約 1750 億パラメータで超高性能なモデルだと報告がありましたが、モデルは公開されず大企業しか LLM に関して研究等が出来ませんでした。その中で 2023 年 2 月に Llama1 が Meta から発表されたわけですが、Llama はいくつかの興味深い報告がありました。
- 70 億から 650 億パラメータのモデルを複数を公開(非商用利用のみ)
- 130 億パラメータのモデルが多くのベンチマークで GPT-3 を凌駕
- モデルスクリプトや学習データを公開
Llama1 の学習データ3
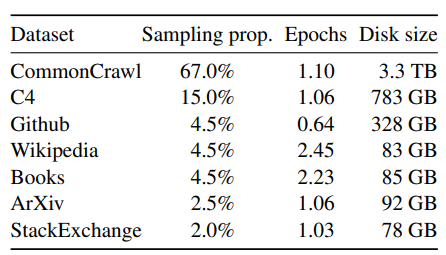
Llama では学習データの大部分が CommonCrawl というデータセットです。これは Web 上のコンテンツをクローリングして作成されたもので、多くの LLM は基本的にはこのデータセットで量を稼いでいます。GPT-3 では CommonCrawl のみを学習しており、しかもフィルタリングをしていたので 570GB とのことでしたが、Llama2 では 3.3TB の CommonCrawl のデータセットの他にいくつかのデータセットを使用することで、GPT-3 の約 9 倍のデータセットを使用していることになります4。スケーリング則によりデータ量が重要であることは前述しましたが、Llama2 は GPT-3 よりもデータ量が多いので、パラメータ数が少ない Llama1 でも GPT-3 を凌駕することができたのではないかと思います。
Llama1 のアーキテクチャ
個人的な Llama1 の面白い点はモデルのアーキテクチャが Transformer からほとんど変わっていない点です。つまり Transformer が発表された 2017 年から 2023 年まで色々な Transformer の改善アーキテクチャは出ていましたが、結局使われているのはオリジナル版の Transformer です。これは Transformer が非常に優れたアーキテクチャであること、モデルの性能にはデータセットの量や多様性が大きく関係していることを示していると思います。
以下の内容がオリジナルの Transformer と Llama1 の Transformer の違いです。
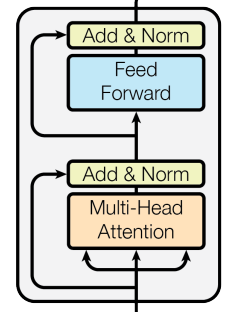
1. Layer normalization の位置を Transformer ブロックの後ろから前に変更
オリジナルの Transformer では Layer normalization は Transformer ブロックの後ろにありましたが、Llama1 では前に移動しています。ただし、Llama1 で新規に提案されたわけではなく、いくつかの LLM (GPT-NeoX など) で既に採用されている手法です。
↓ の Norm を入力部分に持ってくる
2. 活性化関数を Relu から SwiGLU に変更
Deep Learning では活性化関数として Relu を使うことが多いのですが、近年 Relu よりも性能が良いとされる活性化関数はいくつか提案されています。Llama1 では SwiGLU という活性化関数を使っていますが、これも既にいくつかの LLM (Palm など) で採用されている手法です。
3. 位置埋め込みに Rotary embeddings を採用
Transformer では RNN のように構造的に時系列を処理するアーキテクチャではないため、入力に対して位置情報を与える必要があります。Transformer が提案された初期では入力順位(絶対値)を sin/cos 関数でエンコードしていましたが、相対的な位置を使う手法なども提案されてきました。その中で Llama1 では回転行列を使った相対的な位置埋め込み手法である Rotary embeddings を採用しています。そしてこれもいくつかの LLM (GPT-NeoX など) で既に採用されている手法です。
Llama1 の性能
LLM を評価するベンチマークはいくつかありますが、Llama1 は GPT-3 を凌駕する性能を示しています。以下は Llama1 の性能を示すグラフです。3
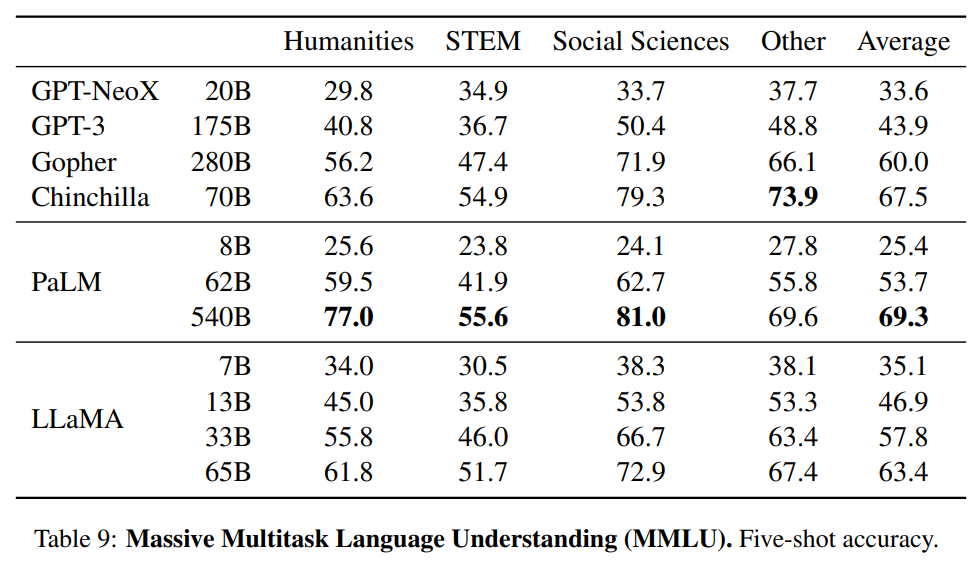
GPT-3 は 175B パラメータで高い性能を持つと話題になりましたが、ベンチマークによってはその 1/10 以下のパラメータ数のモデルでも同等以上の性能を示すことができることが分かります。アーキテクチャは GPT-3 からほぼ進化してきていないことを考えるとこの性能の差はどこで生まれているか気になります。データセット量や多様性、学習方法などが大きく影響していると思います。
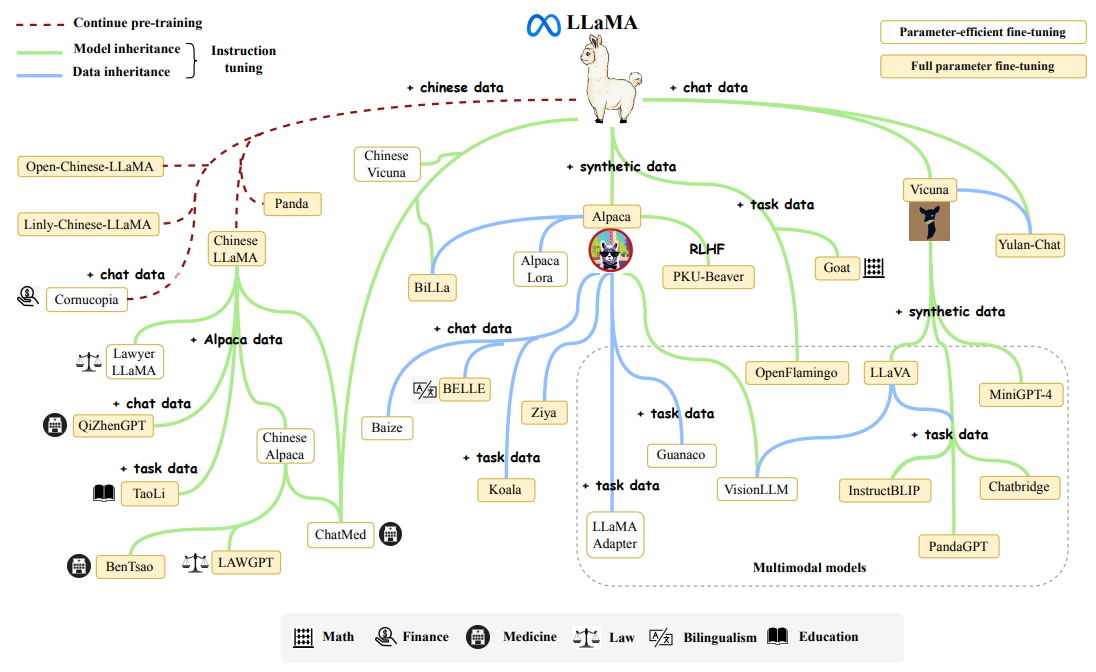
また、オープンに高性能な LLM が公開されたことで Llama1 をベースにさらに追加学習したモデルや、Parameter-efficient fine-tuning(PEFT)とよばれる微調整を加えたモデルなどが公開され、LLM のオープンな研究が活性化しました。
Llama1 の派生モデル1
Llama2 の登場
Llama1 の公開によって盛り上がっていた LLM 界隈ですが、わずか半年後の 2023 年 7 月に Llama2 が登場します。以下のような特徴を持ちます。
- 商用利用可能 (ただし、月間アクティブユーザーが 7 億人を超える場合はライセンス契約が必要)
- 70 億 ~ 700 億パラメータのモデルを公開
- base 版と chat 版の2種のモデルを公開
- helpfulness, safety という 2 軸で評価された報酬モデルの作成
Llama2 のアーキテクチャ
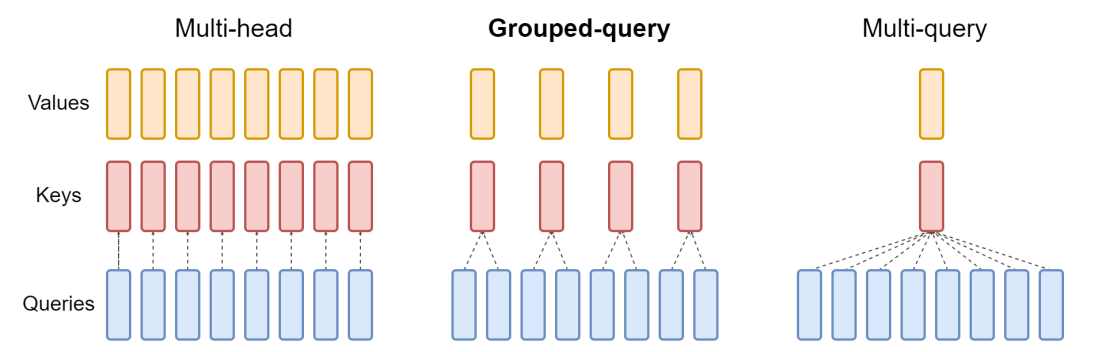
Llama2 のアーキテクチャは Llama1 とほぼ同一です。論文によると違いは入力トークン数の増加(Llama1: 2048, Llama2: 4096)と Grouped-Query Attention (GQA) の採用とのことです。Attention の高速化&省メモリ系のトピックで、Transformer で使われる Multi-head attetion があるのですが、これがコンテキストサイズ(Llama2 では llama1 の 2 倍)やバッチサイズの増加に対してボトルネックになっていました。この問題に対して head 間で共通の Key, Value を使用する Multi-Query Attention が提案されていたり、その中間の手法である Grouped-Query Attention が提案されていました。Llama2 では Grouped-Query Attention を採用しています。この Grouped-Query Attention は Google Research が 5 月に提案していた手法なので、直近の研究をすぐさま取り入れていることに驚きます。また、GQA を適用しているのは 34B と 70B のモデルだけらしいので、多くの人がローカルで動かせる小さなモデルでは GQA は適用されていません。
GQA のイメージ5
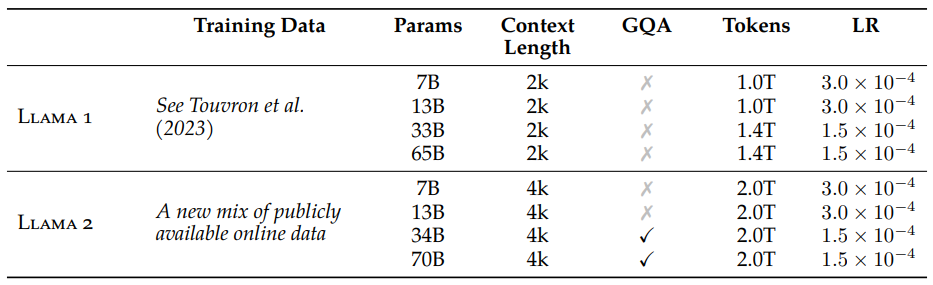
Llama2 の学習データセット
Llama1 では詳細に学習データが公開されていましたが、Llama2 では残念ながら詳細な内容は公開されませんでした。学習したトークン数は公開されており、Llama1 の 1.4 ~ 2.0 倍ぐらいの量のデータを学習したとのことです。 なお、Meta のサービスで入手できるデータは含まれておらず public なデータのみで学習していると強く書いてありました。
Llama2 の学習データ6
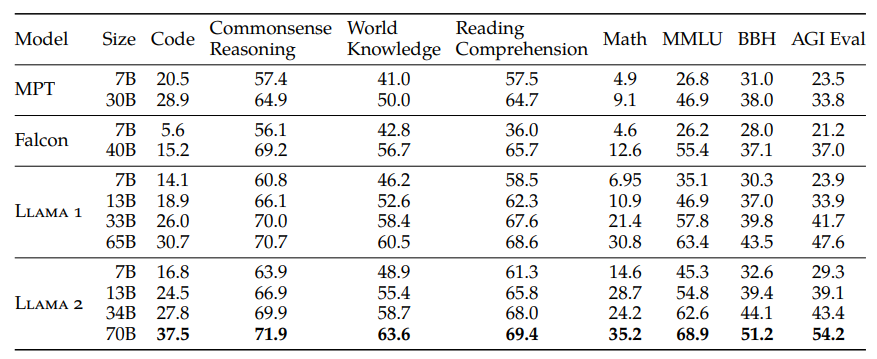
Llama2 base 版の性能
Llama2 base を他のオープンなモデルと比較した結果6
Llama2 base をクローズドなモデルと比較した結果6
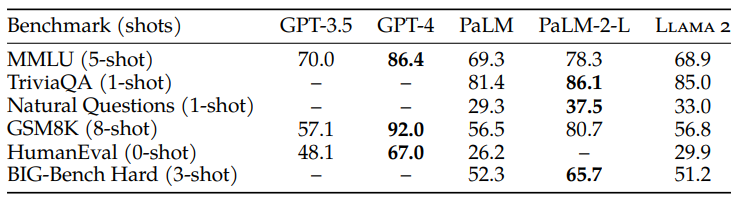
この結果を見ると base 版で既に他のオープンなモデルと比較すると現状トップクラスの性能を有していることが分かります。また、GPT-4 や PaLM2 などのクローズドなモデルと比較すると性能としてはかなり劣勢ですが、GPT-4 は複数のモデルで構成されている/膨大なパラメータ数だったり、PaLM2 は 340B パラメータとのことなので、70B パラメータのモデルでこれだけの性能を出していることはかなり優秀であると思います。
Llama2 の instruction tuning
Llama2 では事前学習の大規模化が行われていますが、Llama1 との大きな違いとして事前学習後の instruction-tuning で特に力を入れていることが挙げられます。
Llama2 の学習過程6
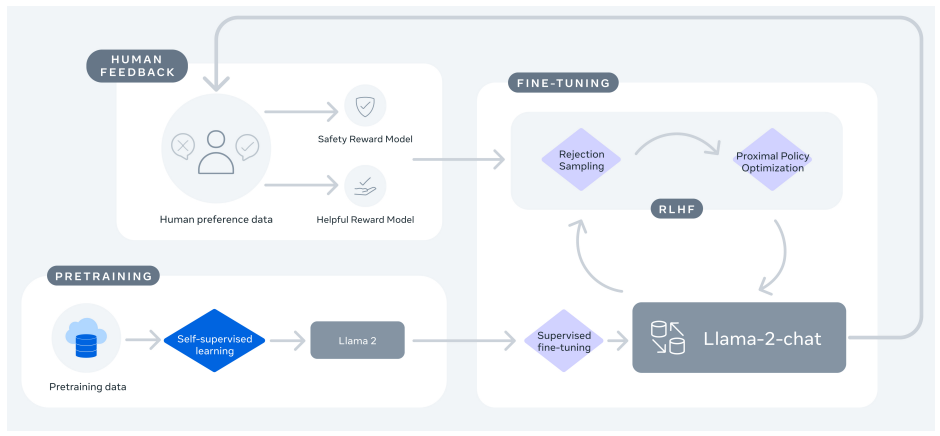
- 大量のパブリックデータでの事前学習 (この時点で base モデルは完成)
- 高品質な instruct dataset での教師あり学習(SFT; Supervised Fine-Tuning)
- 人間フィードバックを用いた強化学習(RLHF; Reinforcement Learning from Human Feedback)
Instruction データは品質が最重要?
前述したように多くの LLM では事前学習の後に指示データ(instruction dataset)を学習させてさらに高性能で人の指示にうまく従ってくれる instruction モデルを作成します。 Llama2 でも同じように instruction dataset を使って SFT をするのですが、公開されている instruction dataset を学習した後、人手で作成した品質が高いデータでも学習したらしい。 論文ではQuality Is All You Needと記載がありましたが、1 万件程度の高品質な instruction データセットで高い精度を達成するには十分だと述べています。最終的には 27,540 件のデータセットになったらしいです。
RLHF で人間のフィードバックを学習
Llama2 では SFT の後 RLHF によってさらに学習を行います。ざっくり説明すると、LLM に複数の回答を出してもらうと、その回答には良い回答や悪い回答という差が出来ると思います。それを人間は順位付けをすることが出来るのでそのデータセットを作ります。 ただし、そのデータセットはそのままでは LLM の学習に使用することが出来ないので、強化学習という手法で学習させます。得点付けのデータセットを学習すれば回答を人間のように点数付けできる報酬モデルが出来るので、その報酬モデルがより得点が高い出力となるように LLM を学習させます。 この辺は ChatGPT の前身である InstructGPT 等と同じような手法なので、詳しくは InstructGPT の解説ページを見るとよく理解できると思います。
面白いのがこの"良い回答"、"悪い回答"は複数の観点で評価できるという点です。Llama2 では helpfulness と safety という 2 軸で評価をしています。helpfulness ではどれだけユーザの要求を満たし、safety では安全性をどれだけ保てるかを評価しています。 論文では爆弾の詳細な作り方を教えるという例が挙げられていて、helpfulness は高いが safety は低くなるとしています。Meta としてはオープンに公開する以上、安全性を保つことへの責任があると考えているようです。
そして helpness と safety それぞれで評価されたデータセットで学習された 2 つの評価モデルを使用して RLHF を実施したとのことです。
Llama2 chat 版の性能
Llama2 chat と他のモデルを人間が helpfulness の観点で評価した結果6
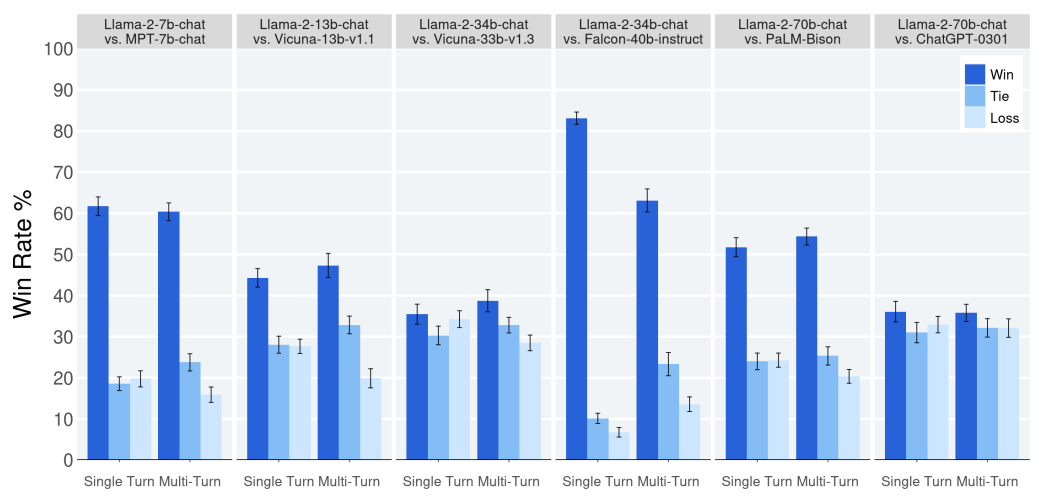
この結果を見ると、Llama2 chat 版はその他の instruct tuning された LLM と比較しても高い性能を誇っていることが分かります。世界中で話題になった ChatGPT と比較しても同等以上の結果となっています。 一点注意をしておきたいのは、この評価は英語のものなので日本語での性能はまた違うということです。体感的には Llama2 よりも ChatGPT の方が日本語ではまだ強いような印象を受けます。
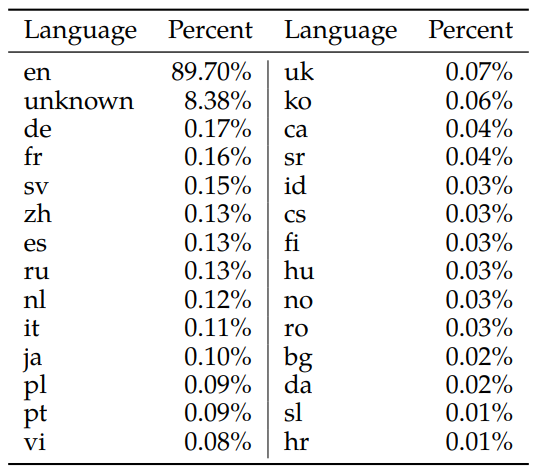
というのも Llama2 の学習において日本語はわずか 0.1%しか含まれていないためです。6
まとめ
今回は大規模言語モデルの基礎的な部分の振り返りから、最新言語モデルの Llama1、Llama2 の特徴を紹介しました。 スケーリング則ではモデルサイズやデータセットサイズがモデルの性能に大きな影響を与えますが、Llama2 などの最近のモデルで実施されているように、事前学習以降の instruction tuning や RLHF による性能向上も性能に大きな影響を与えていることが分かります。
弊社紹介
私が現在所属している TC3 では最新の LLM を活用したソリューションの提供をしていたり、最先端の AI 知識を持つフリーランスの方と一緒にプロジェクトを進めています。
TC3 は「Gig Innovated.」のスローガンを掲げ、ギグ・エコノミーとの共創を通してソフトウェア開発や AI 開発を支援する会社です。ギグ・エコノミーとの共創による開発には、ツール、プロセスなどの観点で様々な課題も存在しています。 このような世界を一緒に作っていく仲間を TC3 では募集していますので、カジュアル面談などお気軽にお問い合わせください!(参考:リクルートサイト)
Footnotes
-
Training language models to follow instructions with human feedback: URL ↩
-
LLaMA: Open and Efficient Foundation Language Models: URL ↩ ↩2
-
厳密には 1epoch だけ学習するわけではないので単純にデータセットサイズでの比較はできません。 ↩
-
GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints: URL ↩
-
Llama 2: Open Foundation and Fine-Tuned Chat Models: URL ↩ ↩2 ↩3 ↩4 ↩5 ↩6